- Apr 28
A Deep Architecture Review of Claude Code: 5 Critical Gaps That Reveal the Future of Agentic AI

1. Why Claude Code Deserves a Deep Architecture Review
A new 46-page study reverse-engineers Claude Code’s architecture from its open-source TypeScript codebase. Its key insight is simple but important: Claude Code is not just a better coding assistant. It is an early example of AI moving from conversation into controlled execution.
Claude Code places a model inside an operating environment where it can read files, edit code, run shell commands, invoke tools, manage context, delegate work, persist sessions, and recover from failures. Once AI can act inside a real software environment, the evaluation standard changes. The question is no longer only whether the model produces a good answer. The harder question is whether the system can act safely, reliably, and accountably.
That is why Claude Code is more than a product story. It is an architecture story.
The study, “Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems,” [Ref-1] shows that the core agent loop is relatively simple. The real sophistication sits around the loop: permission modes, action classification, context compaction, Model Context Protocol integration, plugins, skills, hooks, subagent delegation, and append-oriented session persistence.
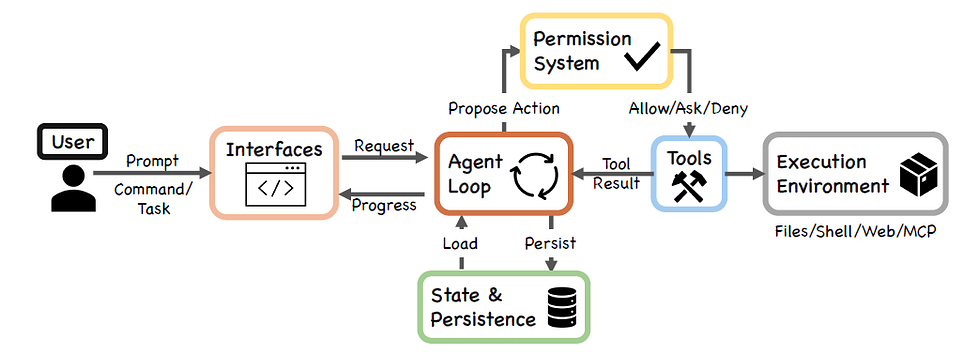
Figure-1: High-level system structure of Claude Code (Ref-1)
This surrounding architecture is what many AI discussions still miss. The model provides intelligence, but the harness gives that intelligence structure.
The tool layer gives it the ability to act.
The context layer shapes what it knows.
The persistence layer gives it continuity.
The permission and governance layers determine whether autonomy remains controlled, auditable, and useful.
This article combines two perspectives.
The first is the paper’s source-level architecture review: how Claude Code appears to work internally.
The second is an agentic engineering review from AEI, the Agentic Engineering Institute, focused on what this architecture reveals about production readiness, enterprise risk, and real-world deployment.
Together, these two perspectives provide a broader and deeper review. The source-level review explains the mechanics of Claude Code. The agentic engineering review explains what those mechanics mean for organizations trying to build, operate, and govern production-grade agentic AI.
Claude Code is impressive because it shows how far agentic AI has advanced. It is even more important because it exposes five engineering gaps that every production-grade agentic system must solve:
Runtime governance: controlling agent actions while the system is operating
Lifecycle trust: maintaining trust across sessions, tools, plugins, updates, and delegation
Context integrity: ensuring memory and context improve decisions instead of distorting them
System-level quality: measuring whether local agent actions improve global outcomes
Human capability preservation: preventing short-term productivity gains from weakening long-term engineering judgment
Claude Code is not just another coding tool. It is an early reference case for the agentic stack, and it shows where the future of agentic AI will be decided: not in the model alone, but in the architecture around the model.
2. The Architecture Lesson: The Model Is Not the System
The biggest lesson from Claude Code is also the one the AI industry keeps underestimating:
A powerful model does not make a production agent.
Community analysis of the extracted Claude Code source estimates that only about 1.6% of the codebase is AI decision logic, while the remaining 98.4% is operational infrastructure. The exact percentage may vary by methodology, but the direction is clear: the intelligence of an agentic system is not located only in the model. It is distributed across the runtime around the model.
Claude Code makes this visible. The model does not directly access the filesystem, run shell commands, or call external services. Instead, it emits structured tool-use requests. The surrounding runtime parses those requests, checks permissions, dispatches tools, collects results, updates state, and feeds the outcome back into the loop.
In simple terms: the model reasons, but the runtime governs action.
That separation is the architecture lesson. Claude Code’s core loop is relatively simple: assemble context, call the model, receive tool requests, approve or reject actions, execute tools, return results, and continue. The real production system lives around that loop:
permission modes
command-risk classification
context compaction
Model Context Protocol integration
plugins, skills, and hooks
subagent delegation
session persistence
This is why Claude Code should not be understood as “a model that codes.” It is better understood as a model-driven execution system.
That distinction matters for enterprise AI. Many organizations still evaluate agentic AI at the model layer: Which model is smarter? Which assistant writes better code? Which demo looks more impressive?
But production failure usually happens at the system layer. Agents fail when authority is unclear, tools are exposed without boundaries, context is compressed without visibility, subagents drift, logs exist without meaningful evaluation, or humans remain accountable for systems they no longer fully understand.
Claude Code points to a more mature conclusion:
The model is not the system. The agentic runtime is the system.
Once we see that, the five critical gaps become unavoidable: runtime governance, lifecycle trust, context integrity, system-level quality, and long-term human capability preservation.
3. Gap 1: The Runtime Governance Gap
The first critical gap Claude Code exposes is the one every enterprise should confront first:
Governance cannot stop at model approval. It must govern the moment of action.
Most AI governance programs were built for systems that generate outputs. Review the model. Approve the use case. Monitor the response. Keep a human in the loop.
That logic breaks when AI starts acting.
An agent does not only answer. It can run commands, edit files, invoke tools, call external services, access repositories, and trigger downstream changes. In that world, the dangerous moment is not when the model thinks. The dangerous moment is when the model acts with delegated authority.
Claude Code Design
Claude Code’s design recognizes this problem.
The model does not directly touch the environment. It proposes actions through structured tool-use requests. Those requests must pass through a runtime permission system before they can execute.
That design choice matters. It separates reasoning from authority.
The model can decide what it wants to do. But the runtime decides whether the action is allowed.
Claude Code uses multiple control mechanisms around this boundary: permission modes, deny-first rules, tool pre-filtering, hooks, an auto-mode classifier, shell sandboxing, and session-scoped permission behavior. This is not traditional AI safety as a policy document. It is safety embedded into the execution path.

Figure-2: Permission gate overview and design principles (ref-1)
The architecture is telling us something important: once an AI system can act, governance must become part of the runtime.
Paper Review
The paper shows that Claude Code routes tool invocations through a layered authorization pipeline. Every tool invocation passes through the permission system, and the default behavior is to deny or ask rather than silently allow. It identifies deny-first rule evaluation, permission modes, hooks, classifier-based evaluation, sandboxing, and tool pre-filtering as part of the control structure.
The paper also highlights a crucial human-factors problem: users approve roughly 93% of permission prompts. That means interactive approval cannot be the only safety mechanism. If humans approve almost everything, the approval button becomes less like governance and more like friction.
This is the paper’s deeper architectural insight: Claude Code is not relying on the human to carefully supervise every action forever. It uses runtime controls because human attention is unreliable at scale.
The paper also notes that Claude Code’s permission model spans multiple modes, from plan and default modes to more autonomous modes such as acceptEdits, auto, dontAsk, and bypassPermissions. Deny rules take precedence even when allow rules are more specific. That means the system is designed around a conservative execution boundary rather than blind agent autonomy.
AEI Review
From AEI’s agentic engineering and enterprise AI production-grade perspective, Claude Code is moving in the right direction. It pulls governance into the runtime, where agentic risk actually happens.
But this is also the first major gap.
Claude Code shows a strong permission architecture for a developer-facing coding agent. Enterprise agentic AI needs something broader: a runtime governance control plane.
A permission system asks:
Can this action run?
Runtime governance asks:
Should this action be allowed under this authority, in this context, against this system, with this risk level, and with this evidence trail?
That distinction is critical.
Enterprise agents need to connect every meaningful action to authority, policy, risk, data sensitivity, system criticality, approval rights, reversibility, recovery procedures, and audit evidence. It is not enough to know that the agent was allowed to call a tool. The organization must know why it was allowed, who delegated that authority, what boundary applied, what changed, and whether the action can be defended after the fact.
This is where many enterprise agent deployments will fail. They will have logs, but not governance evidence. They will have prompts, but not authority models. They will have tool permissions, but not risk-tiered execution. They will have human approval, but not meaningful accountability.
Claude Code gives us a preview of the right pattern: constrain the agent at the point of action.
AEI’s conclusion: production-grade agentic AI requires runtime governance as an engineered system property. Without it, autonomy becomes unmanaged delegation.
AEI Agentic Enterprise Governance Framework (AEGF™)
C006: Agentic Governance Engineering
A useful agent can complete a task.
A governable agent can complete the task within explicit authority boundaries and prove afterward that it acted within them.
4. Gap 2: The Trust Engineering Gap
The second gap is more subtle than runtime governance, but just as important:
A permission system controls what an agent can do. Trust Engineering controls when, where, how, and under what conditions the agent is trusted to operate.
That distinction matters because agentic risk does not begin only when a tool is called. It can appear earlier: when the system starts, when project configuration loads, when plugins initialize, when MCP servers connect, when hooks register, when memory is injected, when a session resumes, or when a subagent inherits part of the parent’s authority.
In other words, the hard question is not only:
What is the agent allowed to do?
The harder question is:
How was the agent trusted before it was allowed to do anything?
Claude Code Design
Claude Code shows real maturity in how it separates reasoning from execution.
The model does not directly touch the environment. It proposes actions through structured tool requests. The runtime evaluates those requests through permission rules, hooks, classifier checks, sandboxing, and session-scoped permission behavior. Claude Code also avoids blindly restoring session-scoped permissions after resume or fork, which is an important trust reset pattern.
But Claude Code is also highly extensible. It supports MCP servers, plugins, skills, hooks, CLAUDE.md memory files, subagents, and session recovery. Each mechanism expands what the agent can see, invoke, inherit, or modify.
That creates a trust engineering challenge.
The more extensible the agent becomes, the more trust boundaries it creates. A plugin is not just a feature. A hook is not just automation. An MCP server is not just integration. A subagent is not just delegation. Each one is a new place where authority can enter, shift, leak, or become ambiguous.
The architecture therefore raises a deeper question:
Is trust engineered across the full lifecycle, or only checked at the moment of tool execution?
Paper Review
The paper shows that Claude Code implements multiple safety layers: tool pre-filtering, deny-first rule evaluation, permission modes, an auto-mode classifier, shell sandboxing, non-restoration of permissions on resume, and hook-based interception. Any applicable layer can block a tool request.
That is strong action-level control.
But the paper also surfaces the deeper trust problem. It notes that Claude Code’s design includes extensibility mechanisms such as MCP servers, plugins, skills, and hooks, all of which enter the agent loop at different points and expand the action surface available to the model.
Most importantly, the paper discusses vulnerabilities tied to pre-trust initialization ordering, where mechanisms such as hooks, MCP connections, and settings resolution could execute before the interactive trust dialog and full permission enforcement were active. The paper’s point is architectural: the permission pipeline captures the spatial ordering of controls, but not always the temporal ordering of when those controls become active.
That is the Trust Engineering gap.
The paper also warns that defense-in-depth depends on the independence of safety layers. If multiple layers share performance or parsing constraints, they can degrade together. It cites an example where complex shell commands with many subcommands could fall back to a generic approval prompt because deeper parsing created UI freezes.
The lesson is clear: layered permissions are necessary, but not sufficient. Trust must be engineered across lifecycle timing, extension loading, control activation, delegation, and recovery.
AEI Review
From AEI’s agentic engineering and enterprise AI production-grade perspective, Trust Engineering is one of the foundational disciplines for agentic systems.
Enterprise trust cannot be treated as a static permission table. In agentic AI, trust is dynamic. It changes as the agent loads context, discovers tools, invokes extensions, spawns subagents, resumes sessions, modifies state, and interacts with external systems.
A traditional permission model asks:
Is this action allowed?
Trust Engineering asks:
Was the agent operating inside a valid trust boundary from initialization through execution, delegation, recovery, and audit?
That is a much higher bar.
For production-grade enterprise agents, Trust Engineering must define:
when the agent becomes active;
which configuration sources are trusted;
which extensions can initialize;
which tools can be discovered;
which memory can be loaded;
which authority can be inherited;
which subagents can be spawned;
when trust must be reset;
what must be isolated;
what must be reversible;
and what evidence must be preserved.
This is where many enterprise agent systems will be weaker than they appear. They may have permission prompts during tool execution, but no formal trust boundary during startup. They may log actions after the fact, but fail to prove that the correct authority boundary was active before the action. They may isolate the main agent, while allowing plugins, MCP tools, hooks, or subagents to create indirect authority paths.
Claude Code demonstrates serious architectural maturity by separating reasoning from execution and layering controls around action.
But the AEI review points to the next level: trust must become an engineered lifecycle property, not a runtime patch around tool calls.
A permission system protects an action.
Trust Engineering protects the agentic system.
C017: Agentic Trust Engineering
That is the second gap Claude Code reveals. The future of agentic AI will depend not only on whether agents ask before acting, but whether trust is engineered across perception, context, memory, tools, extensions, delegation, recovery, and governance.
5. Gap 3: The Context Integrity Gap
The third gap is where agentic AI becomes dangerous in a quieter way.
Not because the model fails.
Because the model may continue working with a compressed, partial, outdated, or distorted version of reality.
For a chatbot, context is mostly conversation history. For an agent, context is much more consequential. It defines what the agent sees, which rules it follows, which tools it understands, what files it has read, what errors it remembers, what prior decisions it carries forward, and what evidence it uses before taking action.
In agentic AI, context is not background information.
Context is the agent’s operating reality.
When that reality changes silently, the agent may not stop. It may continue with confidence.
That is the Context Integrity Gap.
Claude Code Design
Claude Code treats context as an engineered runtime resource.
That is the right instinct. A coding agent quickly accumulates too much state: user instructions, project rules, tool schemas, file contents, shell outputs, test results, logs, prior messages, subagent summaries, compacted summaries, and memory files. If everything is pushed into the model window, the system becomes expensive, noisy, slow, and unreliable.
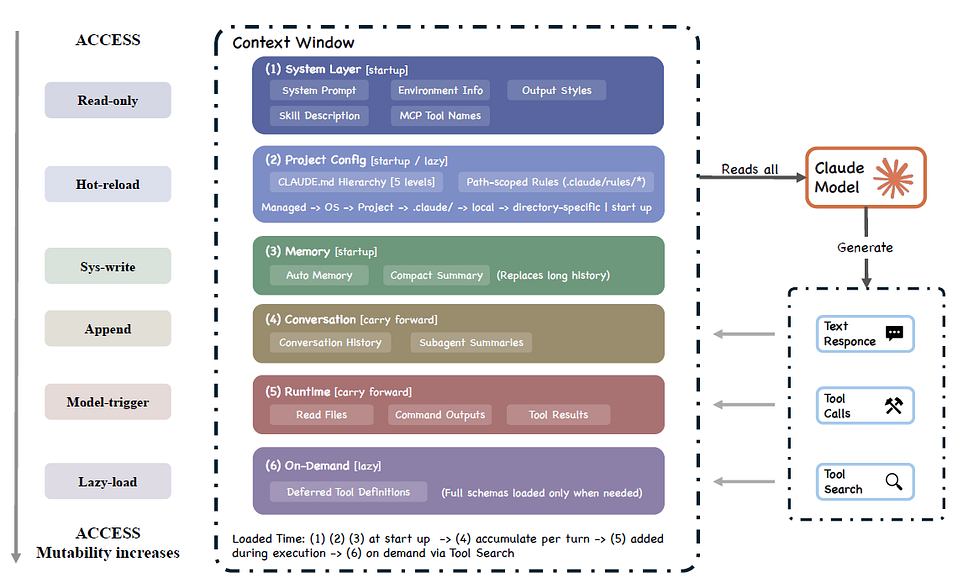
Figure-3. Context construction and memory hierarchy (Ref-1)
So Claude Code does not treat context as a passive prompt. It constructs context from multiple sources: system prompt, environment information, CLAUDE.md instructions, path-scoped rules, auto memory, tool metadata, conversation history, tool results, compact summaries, and deferred tool definitions. Some context loads at startup. Some accumulates during execution. Some is injected late. Some is loaded only when needed. The paper describes this as a context window assembled from many sources, including CLAUDE.md, auto memory, tool metadata, conversation history, tool results, and compact summaries.
That is not prompt engineering.
That is context architecture.
Claude Code also uses progressive compaction to manage context pressure. Instead of relying on one blunt truncation method, it uses multiple techniques: per-tool-result budget reduction, snipping older history, microcompaction, context collapse, and auto-compaction. It also uses lazy loading, deferred tool schemas, summary-only subagent returns, and per-tool-result budgets to reduce context load.
This is sophisticated design. But it creates a second-order risk.
The more context is summarized, collapsed, deferred, or selectively loaded, the more important it becomes to know what the agent is no longer seeing.
Paper Review
The paper’s review is especially valuable because it treats context as a first-class architectural constraint, not a prompt detail.
It identifies the context window as the binding resource constraint in Claude Code. The paper explains that five context-reduction strategies run before model calls because no single method addresses every kind of context pressure. Budget reduction handles oversized tool outputs. Snip handles older history. Microcompact handles cache-aware compression. Context collapse manages long histories. Auto-compact performs model-generated summarization as a later-stage reduction mechanism.
The paper also shows Claude Code’s strength: its memory system is relatively transparent. CLAUDE.md files are plain-text Markdown files rather than opaque database entries. Users can inspect, edit, version-control, and delete the instructions the agent sees. That is a strong architectural choice for trust and auditability.
But the paper also exposes the trade-off. Five interacting compression layers, some feature-gated, can make system behavior difficult for users to predict. Some compaction artifacts are visible, but context collapse can operate as a read-time projection without user-visible output. In plain language: the system may preserve the session while changing the model’s working view of that session.
The paper makes one more important distinction: CLAUDE.md content is delivered as user context, not system-level instruction. That means it guides behavior probabilistically. It does not enforce behavior deterministically. Enforcement still belongs to permission rules and runtime controls.
That distinction is critical.
Context can guide the agent.
Context cannot govern the agent.
AEI Review
From AEI’s agentic engineering and enterprise AI production-grade perspective, Claude Code shows strong context engineering, but it also reveals the deeper enterprise gap: context integrity.
A production agent must not only manage context efficiently. It must make context trustworthy.
The enterprise question is not simply: did the agent have enough context?
The better question is:
Can we prove what context the agent used when it made a decision or took an action?
That is a much higher bar.
In enterprise environments, context may include regulatory obligations, customer commitments, pricing rules, security constraints, architecture standards, operational dependencies, escalation policies, and prior human decisions. If an agent compresses, omits, mis-summarizes, or defers the wrong context, the failure may not look like an error. It may look like a confident, reasonable action based on an incomplete world model.
That is why context integrity must become an engineered system property.
Production-grade agents need context provenance, context-loss visibility, summary validation, memory governance, subagent context boundaries, and traceability between context and action. The organization should be able to reconstruct not only what the agent did, but what the agent believed it knew when it did it.
This is especially important when subagents are involved. Summary-only delegation is efficient, but it creates a knowledge boundary. The parent agent receives the conclusion, not the full reasoning trail. That may be acceptable for speed, but enterprise systems need controls to determine when summaries are sufficient and when full evidence must be preserved.
Claude Code points in the right direction with layered compaction, transparent memory files, lazy loading, deferred schemas, and context-conserving subagent design. But AEI’s conclusion is that context management is not enough for production-grade agentic AI.
Enterprises need context integrity.
Because when an agent loses context, it may not fail loudly.
It may continue with a cleaner, smaller, more confident version of the truth.
C008: Agentic Context Engineering
6. Gap 4: The System-Level Quality Gap
The fourth gap is the one many organizations will discover only after the early productivity numbers look great:
An agent can succeed at the task and still damage the system.
That is the uncomfortable truth behind agentic AI. A test can pass. A file can be fixed. A ticket can close. A workflow can move faster. The demo can look impressive.
And yet the larger system can become worse.
More fragmented. More duplicated. More brittle. More inconsistent. Harder to understand. Harder to govern. Harder to maintain.
This is the System-Level Quality Gap: the gap between local task completion and global system health.
Claude Code Design
Claude Code is designed to make local agent execution effective. It can inspect files, edit code, run commands, invoke tools, iterate on results, and delegate work to subagents. When a task becomes exploratory or too large for the main context, Claude Code can use subagents such as Explore, Plan, general-purpose, verification, or custom agents.
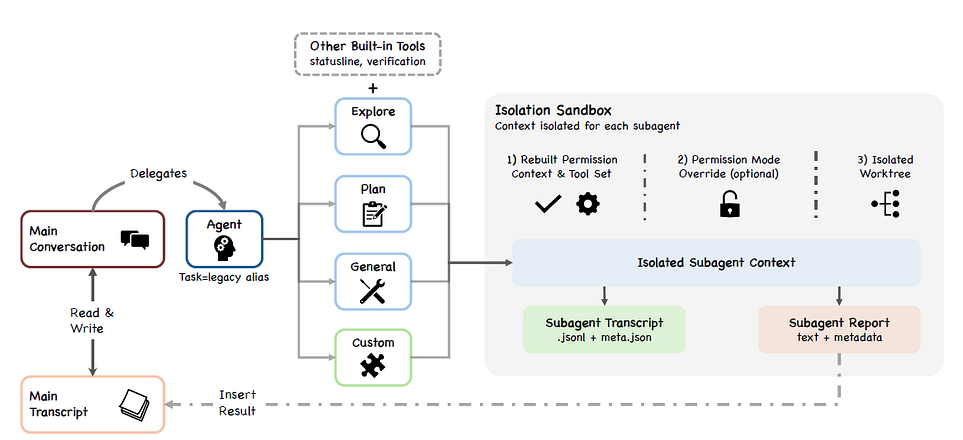
Figure-4: Subagent isolation and delegation architecture (ref-1)
That design is smart. Subagents create separation. They reduce context pressure. They let specialized work happen without flooding the parent session with every intermediate step. In some modes, worktree isolation also gives a subagent a separate filesystem workspace, which helps contain changes.
But isolation has a cost.
A subagent may solve its local assignment while missing the broader architecture. It may not see the full pattern language of the codebase. It may not understand the deeper design intent. It may return a clean summary that hides the assumptions, trade-offs, or uncertainty behind the work.
That is the architectural tension: the same isolation that makes agentic work scalable can make global coherence harder to preserve.
Claude Code is not wrong to use this design. The design is necessary. But it exposes a general truth about agentic systems:
Agents are very good at optimizing the visible task. Enterprises need them to preserve the invisible system.
Paper Review
The paper describes Claude Code’s subagent architecture as a deliberate context-conservation mechanism. Subagents operate in isolated context windows, write separate sidechain transcripts, and return summary-only results to the parent conversation. This prevents subagent histories from overwhelming the parent context and supports longer-running work.
That is a strong production pattern.
But the paper also identifies the risk. Bounded context limits full codebase awareness. Subagent isolation can compound that limitation because different agents may make locally reasonable decisions without sharing a complete global view. The paper specifically points to risks such as pattern duplication, convention violations, and poor global outcomes when agents operate with limited context.
This is one of the paper’s most important architecture-level observations.
The paper also connects this concern to broader empirical signals from adjacent AI coding systems. It cites research showing that AI-assisted development can increase code complexity, including a reported 40.7% increase in complexity in a causal analysis of Cursor adoption, where an early velocity spike later dissipated. It also cites a large-scale audit of AI-authored commits showing measurable technical debt, with some AI-introduced issues persisting into later revisions.
The lesson is not that coding agents are bad.
The lesson is that velocity is not quality.
A local fix can pass the test and still weaken the architecture. A generated function can work and still duplicate an existing pattern. A subagent can produce a correct summary while omitting evidence future maintainers need. A workflow can finish faster while quietly increasing operational debt.
Claude Code’s architecture helps the agent complete work. The unresolved question is how agentic systems prove that the work improved the system rather than merely moved the task forward.
AEI Review
From AEI’s agentic engineering and enterprise AI production-grade perspective, this gap is critical because most organizations will measure agentic AI too narrowly.
They will count tasks completed, tickets closed, pull requests generated, reports produced, cycle time reduced, or hours saved. Those metrics are useful, but they are not enough. They measure throughput. They do not measure system health.
Enterprise-grade agentic AI must answer a harder set of questions:
Did the agent preserve architecture coherence? Did it follow enterprise standards? Did it increase or reduce technical debt? Did it duplicate logic? Did it violate hidden dependencies? Did subagent outputs align with the larger system design? Did the result remain maintainable after the immediate task was done?
This is why AEI separates agent observability from Agentic Quality Assurance.
C004: Agentic Observability Engineering
C019: Agentic Quality Assurance
Observability tells you what the agent did.
Agentic Quality Assurance determines whether what the agent did was correct, coherent, safe, maintainable, and valuable.
That distinction matters because many enterprise failures are not dramatic. They are cumulative. One local workaround. One duplicated rule. One inconsistent integration. One missing control. One summary that hides the wrong assumption. Individually, each looks manageable. Together, they become system decay.
Software teams already know this pattern. Bad code often does not fail immediately. It ships, passes tests, and becomes technical debt. Agentic AI can accelerate the same failure mode at machine speed.
The enterprise version is even broader. In operations, agents may resolve cases while weakening policy consistency. In finance, they may accelerate analysis while spreading inconsistent assumptions. In compliance, they may generate documentation while missing control evidence. In product and engineering, they may optimize local workflows while fragmenting end-to-end accountability.
That is why production-grade agentic AI needs system-level quality controls: architecture rules, regression checks, policy validation, independent evaluators, subagent output review, context-to-action traceability, quality gates, and metrics that measure more than task completion.
Claude Code shows a powerful pattern: isolate subagents to manage complexity.
AEI’s conclusion is that isolation must be balanced with coherence.
A fast agent is useful. A reliable agent is better. A production-grade agent must improve the system without quietly degrading the system.
That is the fourth gap Claude Code reveals. The future failure mode of agentic AI will not be that agents cannot complete tasks. It will be that they complete too many local tasks while slowly damaging global quality.
7. Gap 5: The Human Capability Preservation Gap
The fifth gap is the most uncomfortable because it is not only about software architecture.
It is about what happens to human judgment when agents become good enough to do the work, but not yet trustworthy enough to own the consequences.
Claude Code can help developers move faster. It can explore code, edit files, run tests, repair failures, use tools, delegate work, and continue across long-running sessions. That is real capability amplification. But the deeper question is harder:
What happens when AI helps people produce more while understanding less?
That is the Human Capability Preservation Gap.
Claude Code Design
Claude Code is designed to expand what a developer can attempt.
Its architecture gives the user a model-driven execution system: shell access, file editing, tool use, context management, subagents, memory, persistence, and recovery. The system is not merely answering questions. It is helping perform work inside a real development environment.
That is powerful because it shifts the user from manual execution to agent supervision. The developer can ask for a failing test to be fixed, a codebase to be explored, a plan to be generated, or a verification step to be run. Claude Code can carry much of that operational burden.
But this design also changes the human role.
The human is no longer always the person doing the exploration, forming the hypothesis, tracing the dependency, editing the code, and validating the result. Increasingly, the human becomes the reviewer of an agentic process. That can be efficient. It can also become dangerous if the user approves work faster than they understand it.
The risk is not that the human disappears.
The risk is that the human remains accountable while the understanding quietly moves somewhere else.
Paper Review
The paper makes this concern unusually explicit. It identifies five values shaping Claude Code’s architecture: human decision authority, safety and security, reliable execution, capability amplification, and contextual adaptability. But it treats long-term human capability preservation separately, as an evaluative lens rather than a core design value. That distinction matters: the architecture is optimized to help users do more, but it has limited mechanisms explicitly designed to ensure users understand more over time.
The paper also cites evidence that this is not a theoretical concern. It references Anthropic’s own discussion of the “paradox of supervision,” where overreliance on AI can weaken the very skills needed to supervise AI well. It also cites research finding that developers in AI-assisted conditions scored 17% lower on comprehension tests.
That is the warning: AI can improve output while weakening the human capacity to evaluate that output.
The paper expands this concern with broader evidence from adjacent AI coding studies: experienced developers perceiving productivity gains even when measured performance declined, AI-assisted repositories showing increased complexity, and AI-authored code introducing technical debt that can persist. The paper is careful not to claim that Claude Code itself causes all these effects, but it uses the evidence to show why any agentic coding system must confront the sustainability problem.
The paper’s conclusion is especially important: Claude Code substantially amplifies short-term capability, but offers limited mechanisms that explicitly preserve long-term human understanding, codebase coherence, or the developer pipeline. Future systems, the paper suggests, should treat that sustainability gap as a first-class design problem rather than a downstream metric.
AEI Review
From AEI’s agentic engineering and enterprise AI production-grade perspective, this is not a soft human-resources issue. It is a production risk.
Enterprise systems depend on human judgment. Someone must understand the architecture. Someone must review the change. Someone must own the incident. Someone must explain why the system behaved the way it did. Someone must be able to challenge the agent when it is wrong.
If AI accelerates output while reducing human comprehension, the organization does not simply gain productivity. It accumulates comprehension debt.
That debt is dangerous because it is invisible at first. The code still runs. The report still looks polished. The workflow still completes. The dashboard still improves. But over time, fewer people understand why the system works, where the risks sit, which assumptions matter, and what should not be changed.
This is how organizations become faster and weaker at the same time.
AEI’s view is that production-grade agentic AI must be designed to preserve and strengthen human capability, not merely bypass human labor. That means agentic systems need review scaffolds, explanation surfaces, traceable reasoning, learning loops, human skill checkpoints, codebase comprehension checks, and workflows that keep experts cognitively engaged instead of turning them into symbolic approvers.
The goal is not just “human in the loop.”
The goal is human capability in the loop.
A productivity tool helps people move faster. A production-grade agentic system should help people move faster while becoming better at understanding, supervising, and improving the system.
That is the fifth gap Claude Code reveals. The future of agentic AI cannot be measured only by how much work agents complete. It must also be measured by what happens to human judgment, expertise, ownership, and accountability after agents become part of daily work.
8. What These 5 Gaps Reveal About the Future of Agentic AI
The five gaps point to one conclusion:
The future of AI is not more autonomy. It is engineered autonomy.
That is the deeper lesson of Claude Code. It is impressive because it shows how far modern agents have come. But it is more important because it shows where the industry must go next.
Once AI systems can act inside real environments, the central question is no longer whether the model can generate a useful answer. The question becomes whether the full agentic system can act safely, coherently, accountably, and sustainably.
Claude Code gives us a working preview of that future. It separates model reasoning from tool execution. It routes actions through permissions. It manages context as a scarce runtime resource. It exposes extensions through MCP, plugins, skills, and hooks. It delegates work to subagents. It persists sessions through append-oriented logs. It uses recovery mechanisms to keep long-running work moving.
That is why Claude Code matters beyond coding.
It is not just a developer tool. It is an early reference pattern for agentic systems: a model embedded inside a runtime with tools, memory, context, permissions, delegation, persistence, recovery, and governance boundaries.
The paper reaches this conclusion from a source-level architecture perspective. It shows that Claude Code’s core loop is relatively simple, while most of the implementation lives in the surrounding systems: permissions, context management, extensibility, delegation, persistence, and recovery. The paper frames production coding agents as answers to recurring design questions: where reasoning sits, how safety is organized, how context is managed, how tools are exposed, how delegation works, and how sessions persist.
That is the key architectural insight:
Claude Code is not primarily a model story. It is a harness story.
But the five gaps reveal the next layer.
Runtime permissions are not the same as runtime governance.
Trust boundaries are not the same as Trust Engineering.
Context management is not the same as context integrity.
Task completion is not the same as system-level quality.
Capability amplification is not the same as human capability preservation.
This is where AEI’s agentic engineering review becomes essential.
From an enterprise AI production-grade perspective, the question is not simply whether Claude Code is well designed. It clearly is. The more important question is what its architecture reveals about the production standard every serious enterprise agent will eventually need.
The answer is a new engineering discipline.
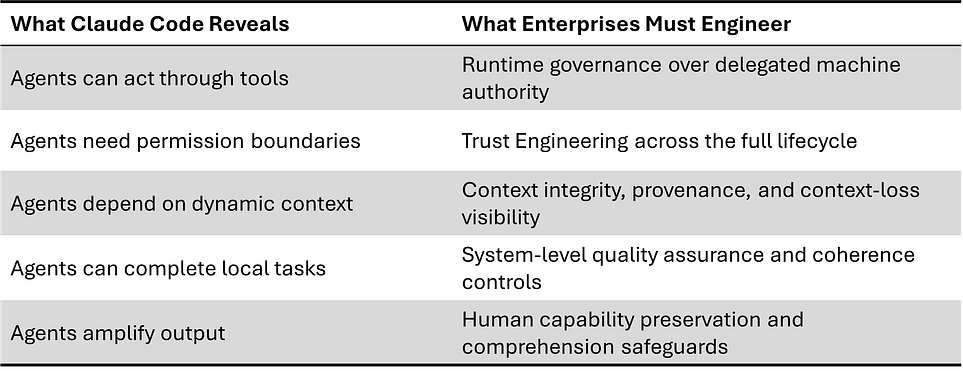
This is the shift many organizations will underestimate.
Agentic AI is not just a productivity layer. It is an operating layer. It touches tools, systems, workflows, data, decisions, institutional memory, and human accountability. That makes it far more powerful than traditional AI assistants, and far more dangerous when under-engineered.
A company can buy access to a frontier model. It can deploy a coding assistant. It can connect tools through MCP. It can automate workflows. It can generate impressive productivity metrics.
None of that proves the system is production-grade.
A production-grade agent must operate inside explicit authority boundaries. Its context must be trustworthy. Its tools must be governed. Its subagents must remain coherent. Its outputs must be evaluated. Its actions must be auditable. Its failures must be recoverable. Its use must strengthen human judgment rather than hollow it out.
That is what the five gaps reveal.
The next AI race will not be won by organizations that simply give agents more autonomy. It will be won by organizations that can engineer autonomy into systems that are governable, inspectable, reliable, and human-strengthening.
Claude Code shows the agentic future arriving.
The deeper lesson is what must be engineered before that future can be trusted.
9. Why This Is Agentic Engineering
Claude Code is one of the clearest examples of the divide I wrote about in my previous article, “Harness Engineering vs. Agentic Engineering: The Hidden Divide Shaping Enterprise AI.”
The argument was simple:
Harness the model. Engineer the system.
Claude Code makes that divide visible.
The paper shows that Claude Code’s core agent loop is relatively simple: call the model, run tools, return results, and repeat. But the real architecture lives around that loop: permissions, context management, extensibility, subagents, persistence, and recovery. In other words, Claude Code is not powerful because the model sits alone. It is powerful because the model is harnessed inside an execution environment that gives it tools, boundaries, memory, and feedback.
That is harness engineering.
Harness engineering gives the model hands. It connects the model to tools. It structures the loop. It manages context. It routes actions. It captures transcripts. It allows the model to operate inside a real environment instead of merely generating text.
But Claude Code also shows why harness engineering is not enough.
Once a model can act, the enterprise problem becomes larger than the harness. The question is no longer only whether the agent can call tools successfully. The question is whether the full system can be trusted in production.
Can every action be governed?
Can trust be engineered across the lifecycle?
Can context integrity be proven?
Can local agent work preserve global system quality?
Can humans remain capable owners instead of becoming passive approvers?
Those are not harness questions alone. They are agentic engineering questions.
This is where AEI’s review goes beyond a product or source-code analysis. The paper explains how Claude Code is built. AEI’s agentic engineering review asks what this architecture means for enterprises that want to deploy agentic AI safely, reliably, and at scale.
That distinction matters because enterprise agents will not operate only inside local coding tasks. They will touch customer data, regulated workflows, software repositories, financial assumptions, operational systems, compliance evidence, pricing logic, and mission-critical processes. In that world, it is not enough for an agent to complete a task. The system must prove that the task was completed within the right authority boundary, using the right context, through governed tools, with recoverable actions, auditable evidence, and measurable quality.
That is agentic engineering.
It is the discipline of designing, building, operating, and governing AI systems that act with delegated machine authority. It treats runtime governance, Trust Engineering, context integrity, tool control, memory, observability, quality assurance, recovery, operating model design, and human capability as first-class system properties.
Claude Code shows what a serious harness can look like.
AEI’s review shows what enterprises must engineer beyond the harness.
The lesson is not that every company needs to copy Claude Code’s architecture. The lesson is that every serious enterprise agent will need its own version of the same deeper capabilities: runtime control, lifecycle trust, context discipline, system-level quality, auditability, recovery, and human oversight.
This is the hidden divide shaping enterprise AI.
A company can buy access to a frontier model. It can connect tools. It can deploy agents. It can produce impressive demos and productivity metrics.
But that does not mean it has built production-grade agentic AI.
Production-grade agentic AI begins when the organization stops treating agents as smarter assistants and starts engineering them as governed runtime systems.
Harness the model. Engineer the system. That is how enterprises win with AI.
10. The Future Is Not More Autonomous Agents. It Is Better Engineered Agents.
Claude Code shows what modern agents can already do.
The deeper lesson is what they still need.
The paper shows that Claude Code is not a simple prompt wrapper. It is a layered agentic runtime: a model surrounded by permissions, context management, extensibility, delegation, persistence, and recovery. That architecture matters because the next generation of enterprise AI will not only generate outputs. It will act inside real systems.
And action changes everything.
When AI predicts, we worry about accuracy.
When AI generates, we worry about usefulness.
When AI acts, we must govern authority.
That is why the five gaps matter:
Runtime governance determines whether actions are controlled.
Trust Engineering determines whether authority is lifecycle-safe.
Context integrity determines whether the agent’s working reality is reliable.
Agentic Quality Assurance determines whether local task success improves the larger system.
Human capability preservation determines whether AI strengthens people or quietly hollows them out.
The future will not belong to the most autonomous agents.
It will belong to the best engineered ones.
For professionals building this capability: join AEI to learn more agentic engineering.
For organizations adopting agentic AI at production scale: partner with AEI to accelerate your AI journey.
The next era of AI will not be defined by who lets agents do the most. It will be defined by who engineers agents well enough to trust them.
Free AEI Newsletters
Expert insights and updates on Agentic Engineering—delivered straight to your inbox.